







What is web scraping?
Web scraping is the automated process of extracting data from websites that can help businesses unlock valuable insights and make strategic decisions. However, malicious web scraping, where bots are used to extract large amounts of data, such as commercially valuable content, images and sensitive business data, from websites and applications can be detrimental for businesses. The data harvested from this web crawling enables web scrapers to fuel criminal and fraudulent activities such as new fake account registration, account takeover, fake listings and reviews, inventory hoarding, and more.
Apart from fueling numerous types of fraud, scraped data can be sold off to third parties or competitors. Selling off scraped databases of verified customer information on the dark web or pricing details to competitors, or hoarding inventory of limited-edition items for resale later, are some of the easy money-spinning options for fraudsters. Therefore, malicious web scraping can lead to financial and reputational losses for businesses.
Mechanics of web scraping
Usually, web scraping begins with sending a request to a web server to retrieve the HTML content of a webpage. On obtaining the content, parsing techniques are employed to extract the desired data. Attackers also use easily and cheaply available web scraping tools that can handle requests, manage spiders, and process extracted data. The extracted web data is stored in various formats such as CSV,, google sheets, JSON format, or databases for further use.
Some common techniques and technologies that web scrapers use include: HTML parsing, automated headless browsers that simulate human interaction with web pages, API (application programming interface) access, proxy rotation, CAPTCHA solving techniques to deter automated scraping, machine learning to extract information from unstructured text or multimedia content, distributed scraping, and data manipulation.
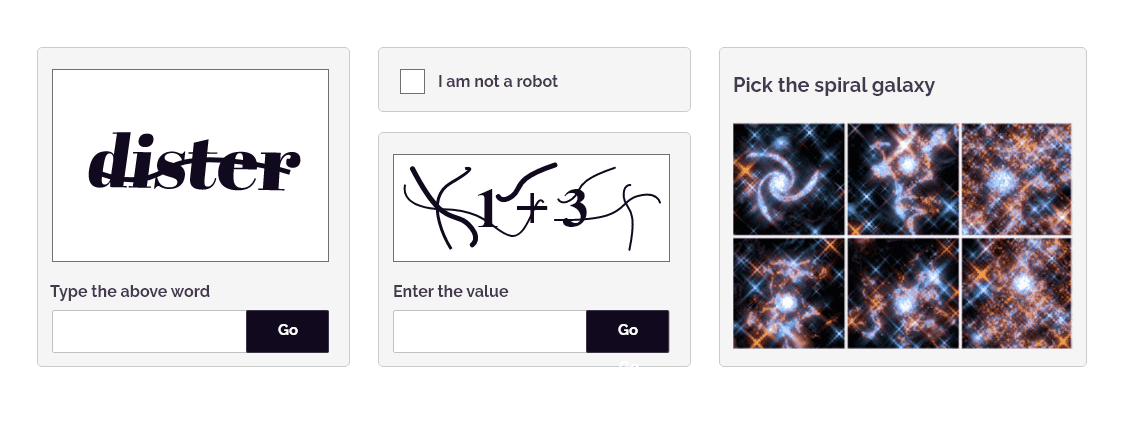
Is website scraping legal?
There are several factors such as the website's terms of service, the nature of the web data being scraped, and applicable laws that help determine whether web scraping is legal or not. While scraping publicly accessible data for personal use or research purposes may be legal, scraping sensitive or confidential data for commercial gain or in violation of a website's terms of service could be illegal.
Web scraping provides marketing teams with a tool for market research, gathering competitive intelligence, monitoring pricing strategies, and tracking market trends in real-time. It also helps with extracting contact information from various sources, streamlining sales and marketing efforts, and generating lead lists. Often, businesses use web scraping to collect customer feedback and analyze sentiment analysis from social media platforms and review websites, enabling them to make strategic decisions.
Researchers, students, and journalists, often scrape web data for studies and analysis across various disciplines. Researchers use web scraping to collect data for sentiment analysis, trend forecasting, and social network analysis, and generate valuable insights.
In today’s digital world, web scraping helps create datasets for machine learning and artificial intelligence applications. By harvesting large volumes of diverse data, researchers and developers can collect labeled or unlabeled data across a wide range of domains to train and test machine learning models, reducing the learning curve and facilitating the development of AI systems for activities such as natural language processing, image recognition, and predictive analytics.
Role of bots in web scraping
Attackers extensively use bots to automate the web scraping process and the repetitive tasks in retrieving and parsing web content. These automated web crawlers can mimic human browsing behavior to retrieve data and navigate websites for efficient and scalable web data extraction. Automation significantly reduces the time and effort required for web scraping tasks, making it possible for web scrapers to access large amounts of data from multiple sources in a relatively short duration.
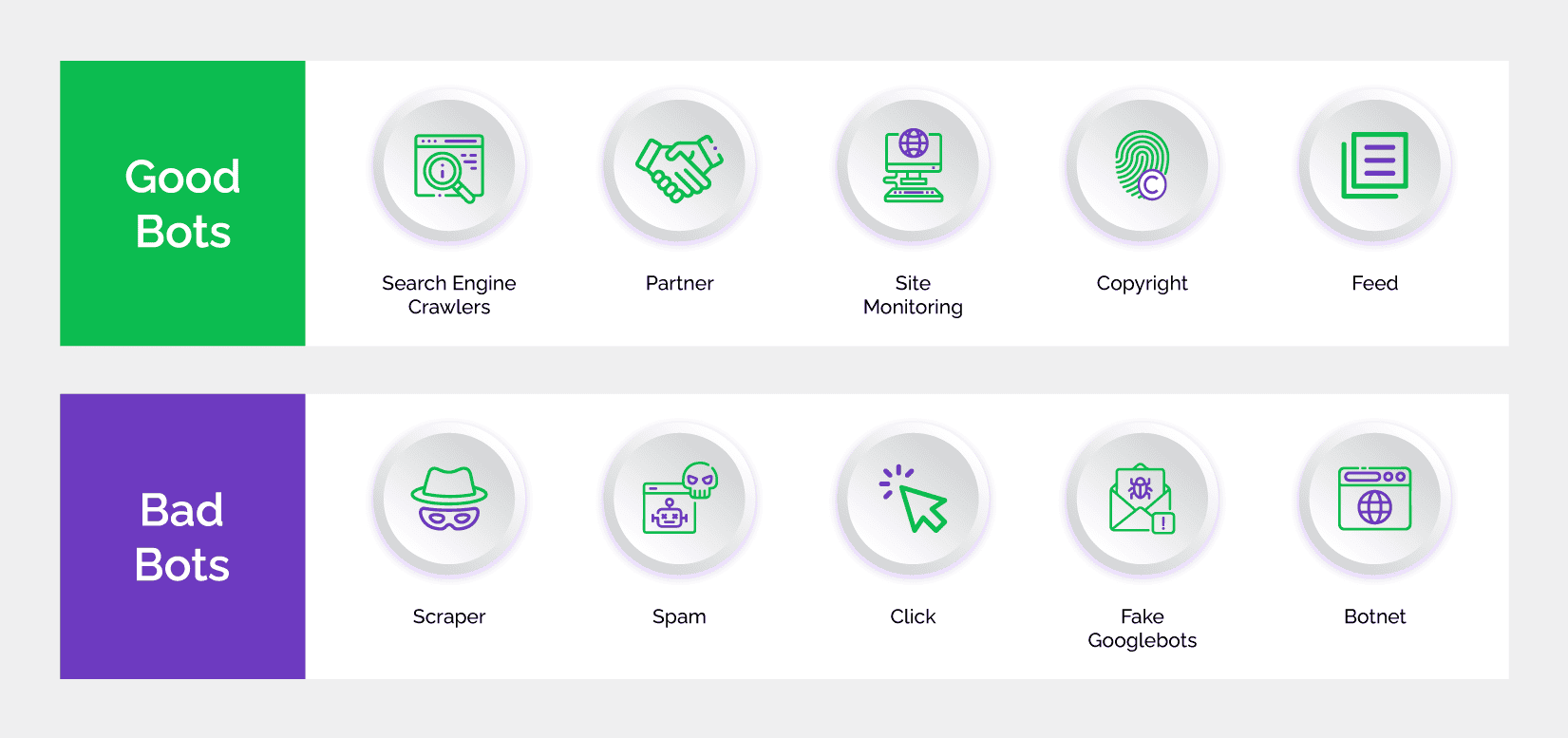
Attackers use specialized software programs or bots, called scraper bots, that are specially designed web crawlers to extract data from target websites for various purposes. These bots navigate the web, sending requests to web servers and parsing the HTML content of web pages to extract information in a structured format. From simple scripts to sophisticated programs capable of mimicking human behavior and evading detection measures, scraper bots are available in various capability levels, according to the needs of the attackers.
A lot of times, attackers program bots to adhere to target website terms of service and robots.txt guidelines, so that they can engage in unethical practices such as screen scraping, extracting copyrighted content, or bypassing security measures. Bot traffic can strain the server resources of the target site and degrade user experience. Furthermore, bots can employ several web crawling techniques to evade detection and bypass anti-scraping measures implemented by websites.
Monetizing scraped data
Attackers are in the business of making money and automated website scraping provides them with a low-investment method to harvest large amounts of business and consumers’ personal data at scale. Some of the common ways attackers use to monetize scraping are as below:
Consumer data
When fraudsters disseminate stolen personal data of consumers, either for free or to monetize it, businesses incur losses. Often, attackers sell the stolen databases to third parties or on the dark web to make money quickly. They also use the stolen data to improvise their attack strategies for more sophisticated and targeted attacks including account takeover, fake new account registration, and spam dissemination.
Business data
Scraping sensitive business data, such as pricing details, and selling them to competitors can lead to extirpating the marketing strategy of a business.
Web content
For many businesses, content is their primary source of revenue. When this content is stolen, these businesses risk losing business viability and their existence is threatened.
Images
Using stolen data and images from social media platforms, fraudsters can create fake social media profiles and impersonate genuine users to request fund transfers from their network of friends. Fraudsters can even morph the pictures and use them to extort money from the users.
Denial of inventory
Attackers can overwhelm business networks with denial of inventory attacks to disrupt business operations and cause losses.
Fake reviews
Using stolen data, fraudsters can downvote products or write fake reviews to tarnish the reputation of a business.
Spam
Stolen email addresses allow fraudsters to disseminate spam and overwhelm users.
Phishing
Databases of scraped user details serve as the building blocks for phishing campaigns that enable fraudsters to dupe unsuspecting users into making wire transfers or divulging confidential information.
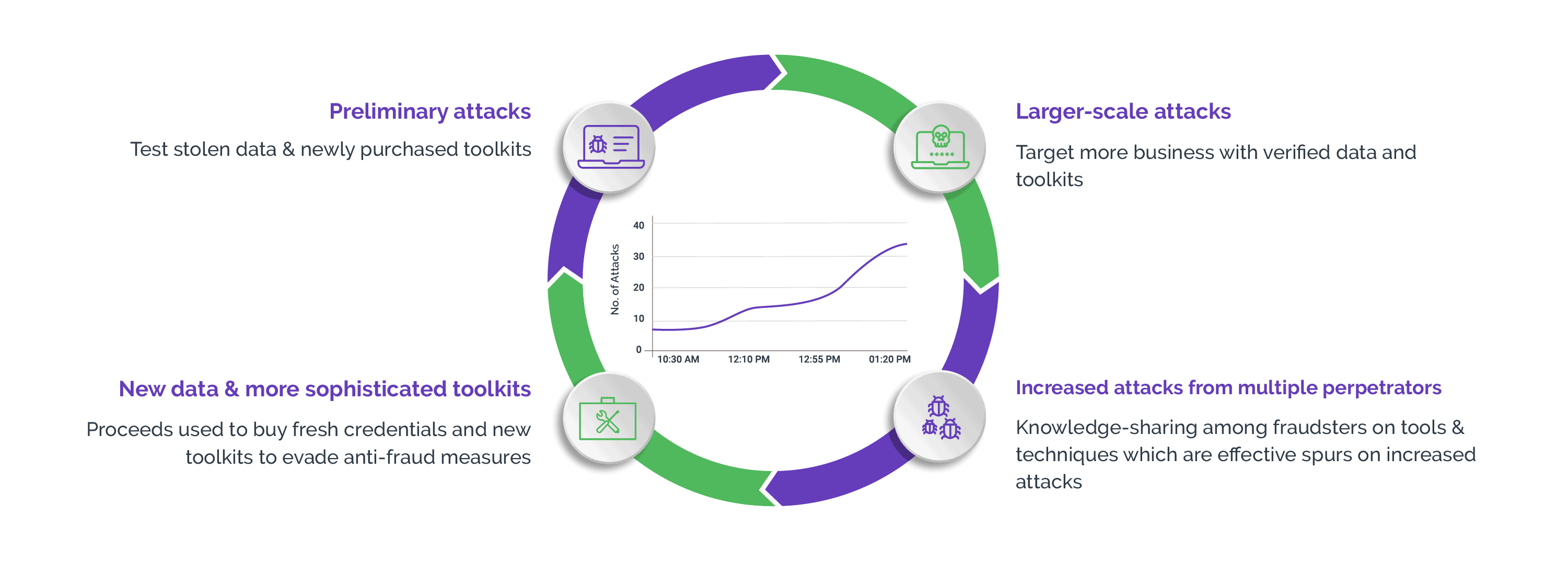
Impact of web scraping on businesses
Website scraping can cause serious damages to business across industries in a number of ways. Scraping bots can overload servers and strain bandwidth, resulting in degradation of website performance and slower response times for genuine users. When bots are programmed to scrape intellectual property or copyrighted data, it can result in unfair competitive advantage for competitors who may use this scraped data to gain insights into pricing strategies, product offerings, and market trends without themselves investing in research and development.
Web scraping can skew the evaluation metrics by causing inaccuracies in relevant data or using outdated data for decision-making. This can result in poor decision-making, lost business opportunities, and weakened competitiveness in the marketplace. Web scraping can seriously undermine the integrity of businesses, disrupt operations, and erode consumer trust, eventually impacting the bottom line and long-term success of the organization. Some ways in which web scraping affects businesses across various industries is as described below:
Social media platforms
Social media scraping can overload servers of social media platforms, leading to slow response times and degraded performance. Web scraping can violate users' privacy by harvesting their personal data without consent and misusing sensitive data for criminal activities. Scraping bots can disseminate spam, create fake accounts, and engage in malicious activities on social media platforms, undermining user trust and the integrity of the platform.
Online dating
By creating fake profiles using scraped data and other relevant information, such as hobbies, interests, and so forth, web scraping on online dating platforms can lead to an influx of spam messages, fraudulent accounts, and deceptive practices to impact the authenticity of the platform. Web scraping can collect and exploit users’ personal information without consent, resulting in violation of users' privacy, identity fraud, or harassment. Furthermore, web scraping can distort user engagement metrics to impact the accuracy of matchmaking algorithms, resulting in subpar user experiences and erosion of user trust.
Fitness apps
Scraping bots can collect user data, such as sensitive health and fitness information, without consent, causing privacy breaches and unauthorized use of scraped data. Distortion of user engagement metrics can affect the accuracy of fitness tracking algorithms, resulting in inaccurate performance measurements and personalized recommendations for users. Additionally, web scraping can facilitate unauthorized access to proprietary workout routines, training plans, and other intellectual property, disrupting the competitive advantage of the app.
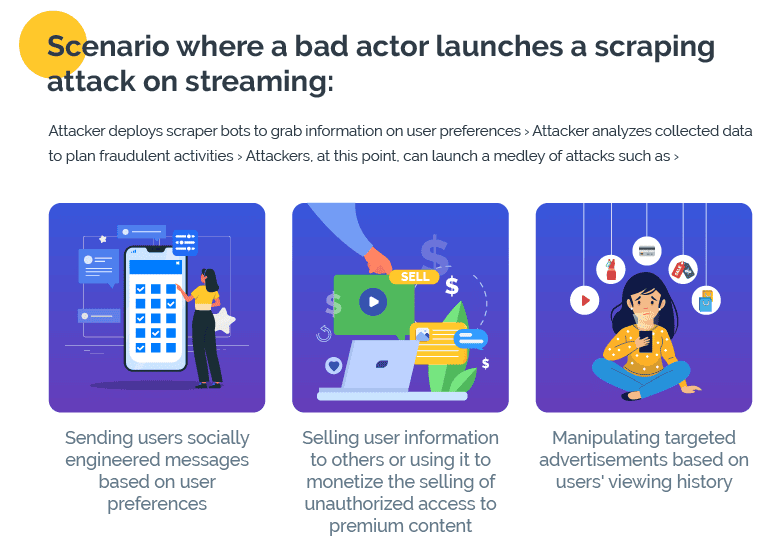
Streaming media services
Scraper bots can degrade streaming quality, cause buffering issues, and disrupt user experience by overloading servers and straining bandwidth. With unauthorized access and redistribution of copyrighted content, web scraping can cause violation of content distribution agreements and copyright laws, exposing the streaming platform to fraud and potential legal action. Web scraping can also disrupt the revenue model of streaming services by circumventing subscription fees and ad revenue, thereby undermining the financial viability of content creators and distributors.
Travel
Web scraping can overload servers and cause delays in data updates, inaccurate pricing information, and availability status, causing consumer frustration. It can enable unauthorized access to pricing data and inventory information, providing competitors with unfair advantage and disrupting the competitive landscape. Furthermore, website scraping facilitates collection of consumers’ personal information, including travel itineraries and preferences, compromising data security and facilitating unauthorized use of sensitive data.
Retail/e-commerce
Inaccurate product prices and manipulation of other useful information can overload servers and delay data updates. This can enable unauthorized access to pricing data, inventory levels, and product descriptions, leading to unfair advantages for competitors and frustrating users. Since web scraping facilitates collection of personal information, including shopping habits and preferences, it can compromise user privacy and allow attackers to misuse sensitive data on eCommerce platforms.
Emerging trends in web scraping
With continuous advancements in technology, data analytics, and regulatory frameworks web scraping too continues to evolve. As bots become more intelligent and acquire human-like capabilities, such as natural language processing and image recognition capabilities, web scraping is becoming more sophisticated. These advancements empower attackers to interact with dynamic web content more effectively and overcome traditional CAPTCHAs rather easily. Attackers are continuously looking for ways to improve bot performance, resilience, and efficiency of scraping operations. As a result, they are increasingly relying on integrating machine learning algorithms into bot frameworks.
AI-driven scraping, decentralized scraping networks, and integration of blockchain for improved data security and transparency are some of the notable trends in web data scraping. On the legal and ethical front, implications of web scraping are becoming increasingly complex as data privacy regulations and norms around data usage continue to evolve.
Why businesses must address web scraping
Web scraping is a high-volume, low-monetization attack vector. Therefore, attackers use automation to achieve sufficient scale and drive return on investment. Theft of confidential consumer data also increases the risk of digital identities being compromised at scale. This is why using bots for web scraping has become a big challenge for today's digital businesses.
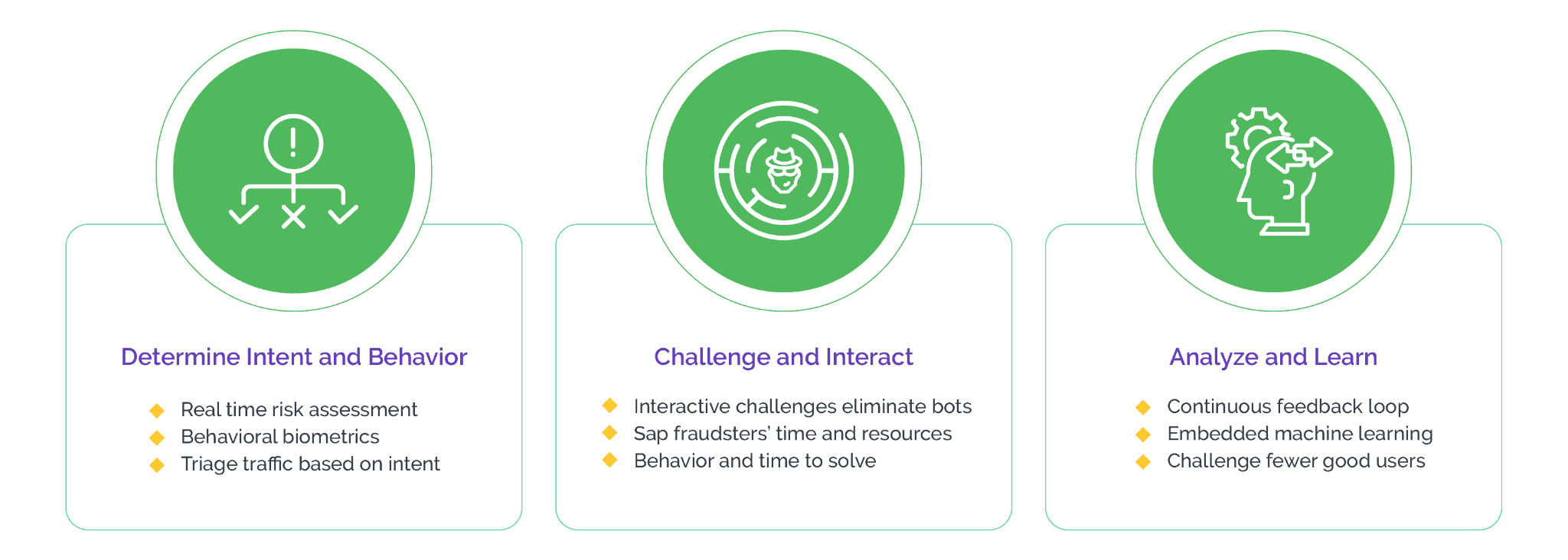
Many businesses analyze customer data to gain insights that guide creation of products or services, ultimately resulting in revenue generation. When attackers scrape and exploit this data, the commercial viability of the business model is put to risk and the existence of the business itself is threatened.
Further, inability to protect consumer data due to unauthorized scraping can make digital businesses non-compliant with data protection laws and regulations, exposing them to fines, penalties, legal action, as well as erosion of customer trust.
Therefore, it is critical that businesses know how to proactively identify and stop automated scraping attempts and mitigate the risk of data exposure.
Challenges in fighting web scraping
Fighting web scraping poses numerous challenges, including the difficulty to accurately distinguish between legitimate and malicious bot traffic. With scraping techniques evolving continuously, attackers can easily bypass detection mechanisms, exposing legitimate users to heightened risks. The increased use of JavaScript frameworks further complicates fighting scraping attempts as it requires powerful tools and expertise.
To protect against bot-powered scraping attempts, digital businesses must remain vigilant and deploy solutions that can stop scraping attempts right at the entry gates. However, legacy defense mechanisms cannot provide the level of protection that businesses need in an ever-changing threat landscape. Free or cheap bot mitigation solutions ultimately cost businesses in many ways, namely: customer churn, damage to consumer trust, and loss of brand image. For instance, CAPTCHAs were designed specifically to protect digital businesses from the onslaught of bot-driven attacks such as scraping. However, while bots have evolved at a great speed, CAPTCHAs have failed to keep pace. This has led to legacy CAPTCHAs being outsmarted by even the basic bots.
As well as bypassing traditional solutions, bots are now advanced enough to mimic human behavior with a certain level of accuracy. They are programmed in such a manner that in an event a more nuanced human interaction is required than what they can handle, they hand over the attack baton to human sweatshops. This makes it all the more challenging for businesses to thwart complex, automated scraping attempts.
Best practices and strategies for effective protection
Effectively fighting automated web scraping requires businesses to adopt best practices, strategies, and powerful tools that can enable them to proactively detect and mitigate automated scraping activity, while minimizing disruption to legitimate users. Some techniques businesses can consider include:
- Respecting robots.txt and website policies: To maintain ethical web scraping practices and avoiding legal repercussions.
- Throttling and rate limiting: To maintain the stability and performance of websites by regulating the frequency and volume of requests.
- Detecting proxy usage and IP rotation: To detect and block risky IPs
- Implementing CAPTCHAs: To present challenges to interrupt automated scraping operations.
- Implementing bot protection software: To safeguard websites, apps and other digital platforms from malicious bot traffic, including scraping bots. Featuring challenges, device fingerprinting, and behavioral analysis, bot protection software analyzes user behavior patterns and distinguishes between legitimate users and automated bots.
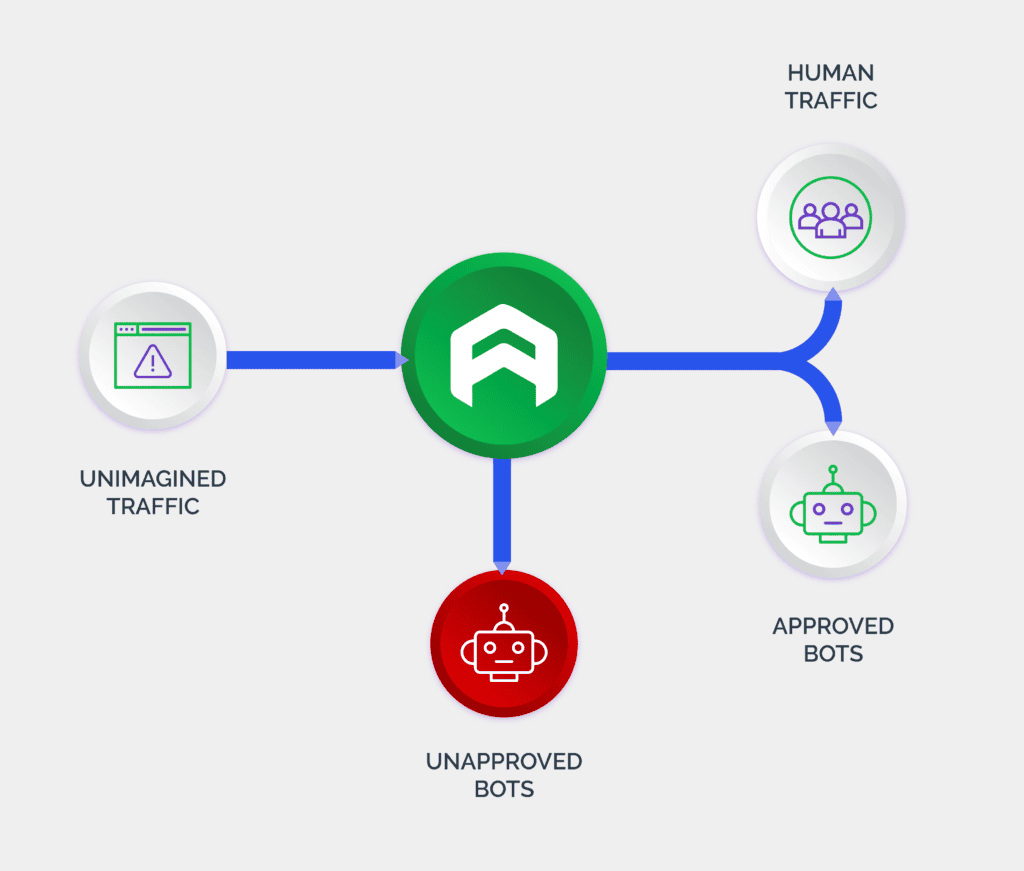
Learn about how Arkose Labs helps businesses stop web scraping attacks.